异步编程的优势与难点
优势
Node带来的最大特性莫过于基于事件驱动的非阻塞I/O模型,这是它的灵魂所在。非阻塞I/O可以使CPU与I/O并不相互依赖等待,让资源得到更好的利用。
对于网络应用而言,并行带来的想象空间更大,延展而开的是分布式和云。并行使得各个单点之间能够更有效地组织起来,这也是Node在云计算厂商中广受青睐的原因,
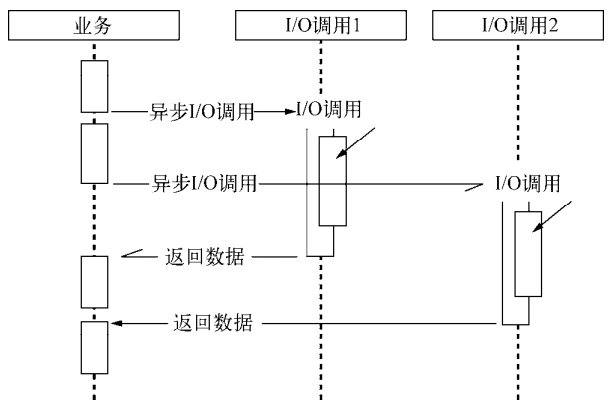
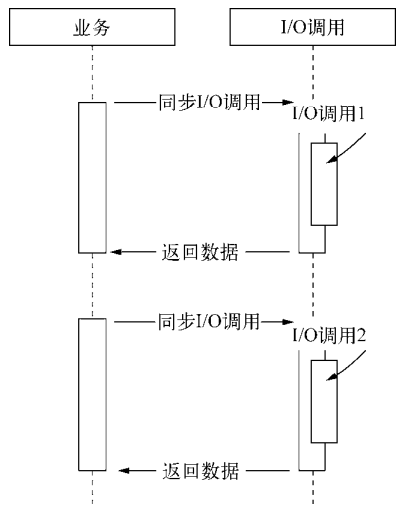
如果采用传统的同步I/O模型,分布式计算中性能的折扣将会是明显的。
Node实现异步I/O的原理是利用事件循环的方式,JavaScript线程像一个分配任务和处理结果的大管家,I/O线程池里的各个I/O线程都是小二,负责兢兢业业地完成分配来的任务,小二与管家之间互不依赖,所以可以保持整体的高效率。
这个模型的缺点则在于管家无法承担过多的细节性任务,如果承担太多,则会影响到任务的调度,管家忙个不停,小二却得不到活干,结局则是整体效率的降低。
换言之,Node是为了解决编程模型中阻塞I/O的性能问题的,采用了单线程模型,这导致Node更像一个处理I/O密集问题的能手,而CPU密集型则取决于管家的能耐如何。
由于事件循环模型需要应对海量请求,海量请求同时作用在单线程上,就需要防止任何一个计算耗费过多的CPU时间片。至于是计算密集型,还是I/O密集型,只要计算不影响异步I/O的调度,那就不构成问题。建议对CPU的耗用不要超过10 ms,或者将大量的计算分解为诸多的小量计算,通过setImmediate()进行调度。只要合理利用Node的异步模型与V8的高性能,就可以充分发挥CPU和I/O资源的优势。
难点
异常处理
过去我们处理异常时,通常使用类Java的try/catch/final语句块进行异常捕获。
try {
JSON.parse(json);
} catch (e) {
// TODO
}但是这对于异步编程而言并不一定适用。
异步I/O的实现主要包含两个阶段:提交请求和处理结果。这两个阶段中间有事件循环的调度,两者彼此不关联。异步方法则通常在
第一个阶段提交请求后立即返回,因为异常并不一定发生在这个阶段,try/catch的功效在此处不会发挥任何作用。
var async = function (callback) {
process.nextTick(callback);
};调用async()方法后,callback被存放起来,直到下一个事件循环(Tick)才会取出来执行。尝试对异步方法进行try/catch操作只能捕获当次事件循环内的异常,对callback执行时抛出的异常将无能为力。
try {
async(callback);
} catch (e) {
// TODO
}Node在处理异常上形成了一种约定,将异常作为回调函数的第一个实参传回,如果为空值,则表明异步调用没有异常抛出。
async(function (err, results) {
// TODO
});在我们自行编写的异步方法上,也需要去遵循这样一些原则:
- 必须执行调用者传入的回调函数;
- 正确传递回异常供调用者判断;
var async = function (callback) {
process.nextTick(function() {
var results = something;
if (error) {
return callback(error);
}
callback(null, results);
});
};在异步方法的编写中,另一个容易犯的错误是对用户传递的回调函数进行异常捕获。
try {
req.body = JSON.parse(buf, options.reviver);
callback();
} catch (err){
err.body = buf;
err.status = 400;
callback(err);
}上述代码的意图是捕获JSON.parse()中可能出现的异常,但是却不小心包含了用户传递的回调函数。这意味着如果回调函数中有异常抛出,将会进入catch()代码块中执行,于是回调函数将会被执行两次。这显然不是预期的情况,可能导致业务混乱。
try {
req.body = JSON.parse(buf, options.reviver);
} catch (err){
err.body = buf;
err.status = 400;
return callback(err);
}
callback();在编写异步方法时,只要将异常正确地传递给用户的回调方法即可,无须过多处理。
函数嵌套过深
对于Node而言,事件中存在多个异步调用的场景比比皆是。比如一个遍历目录的操作。
fs.readdir(path.join(__dirname, '..'), function (err, files) {
files.forEach(function (filename, index) {
fs.readFile(filename, 'utf8', function (err, file) {
// TODO
});
});
});阻塞代码
对于JavaScript,比较纳闷这门编程语言竟然没有sleep()这样的线程沉睡功能,唯独能用于延时操作的只有setInterval()和setTimeout()这两个函数。但是让人惊讶的是,这两个函数并不能阻塞后续代码的持续执行。
var start = new Date();
while (new Date() - start < 1000) {
// TODO
}
// 需要阻塞的代码这段代码会持续占用CPU进行判断,与真正的线程沉睡相去甚远,完全破坏了事件循环的调度。由于Node单线程的原因,CPU资源全都会用于为这段代码服务,导致其余任何请求都会得不到响应。遇见这样的需求时,在统一规划业务逻辑之后,调用setTimeout()的效果会更好。
多线程编程
对于服务器端而言,如果服务器是多核CPU,单个Node进程实质上是没有充分利用多核CPU的。