数据类型
概览
变量(或常量)包含数据,这些数据可以有不同的数据类型,简称类型。使用 var 声明的变量的值会自动初始化为该类型的零值。类型定义了某个变量的值的集合与可对其进行操作的集合。
类型可以是基本类型,如:int、float、bool、string;
结构化的(复合的),如:struct、array、切片 (slice)、map、通道 (channel);
只描述类型的行为的,如:interface。
结构化的类型没有真正的值,它使用 nil 作为默认值(在 Objective-C 中是 nil,在 Java 中是 null,在 C 和 C++ 中是 NULL 或 0)。值得注意的是,Go 语言中不存在类型继承。
函数也可以是一个确定的类型,就是以函数作为返回类型。这种类型的声明要写在函数名和可选的参数列表之后,例如:
func FunctionName (a typea, b typeb) typeFunc你可以在函数体中的某处返回使用类型为 typeFunc 的变量 var:
return var一个函数可以拥有多返回值,返回类型之间需要使用逗号分割,并使用小括号 () 将它们括起来,如:
func FunctionName (a typea, b typeb) (t1 type1, t2 type2)返回的形式:
return var1, var2这种多返回值一般用于判断某个函数是否执行成功 (true/false) 或与其它返回值一同返回错误消息(详见之后的并行赋值)。
使用 type 关键字可以定义你自己的类型,你可能想要定义一个结构体,但是也可以定义一个已经存在的类型的别名,如:
type IZ int这里并不是真正意义上的别名,因为使用这种方法定义之后的类型可以拥有更多的特性,且在类型转换时必须显式转换。
然后我们可以使用下面的方式声明变量:
var a IZ = 5这里我们可以看到 int 是变量 a 的底层类型,这也使得它们之间存在相互转换的可能。
如果你有多个类型需要定义,可以使用因式分解关键字的方式,例如:
type (
IZ int
FZ float64
STR string
)每个值都必须在经过编译后属于某个类型(编译器必须能够推断出所有值的类型),因为 Go 语言是一种静态类型语言。
基本类型
布尔类型 bool
布尔型的值只可以是常量 true 或者 false。当相等运算符两边的值是完全相同的值的时候会返回 true,否则返回 false,并且只有在两个的值的类型相同的情况下才可以使用。
在 Go 语言中,&& 和 || 是具有快捷性质的运算符,当运算符左边表达式的值已经能够决定整个表达式的值的时候(&& 左边的值为 false,|| 左边的值为 true),运算符右边的表达式将不会被执行。利用这个性质,如果你有多个条件判断,应当将计算过程较为复杂的表达式放在运算符的右侧以减少不必要的运算。
对于布尔值的好的命名能够很好地提升代码的可读性,例如以 is 或者 Is 开头的 isSorted、isFinished、isVisible,使用这样的命名能够在阅读代码的获得阅读正常语句一样的良好体验,例如标准库中的 unicode.IsDigit(ch)
数字类型
Go 语言支持整型和浮点型数字,并且原生支持复数,其中位的运算采用补码。
Go 有基于架构的类型,例如:int、uint 和 uintptr。
这些类型的长度都是根据运行程序所在的操作系统类型所决定的:
int和uint在 32 位操作系统上,它们均使用 32 位(4 个字节),在 64 位操作系统上,它们均使用 64 位(8 个字节)。uintptr的长度被设定为足够存放一个指针即可。
Go 语言中没有 float 类型。(Go语言中只有 float32 和 float64)没有 double 类型。
整数:
int8(-128 -> 127)int16(-32768 -> 32767)int32(-2,147,483,648 -> 2,147,483,647)int64(-9,223,372,036,854,775,808 -> 9,223,372,036,854,775,807)
无符号整数:
uint8(0 -> 255)uint16(0 -> 65,535)uint32(0 -> 4,294,967,295)uint64(0 -> 18,446,744,073,709,551,615)
浮点型(IEEE-754 标准):
float32(+- 1e-45 -> +- 3.4 * 1e38)float64(+- 5 1e-324 -> 107 1e308)
int 型是计算最快的一种类型。
整型的零值为 0,浮点型的零值为 0.0。
复数:
complex64(32 位实数和虚数)complex128(64 位实数和虚数)
复数使用 re+imI 来表示,其中 re 代表实数部分,im 代表虚数部分,I 代表根号负 1。
字符类型
严格来说,这并不是 Go 语言的一个类型,字符只是整数的特殊用例。byte 类型是 uint8 的别名,对于只占用 1 个字节的传统 ASCII 编码的字符来说,完全没有问题。例如:var ch byte = 'A';字符使用单引号括起来。
在 ASCII 码表中,'A' 的值是 65,而使用 16 进制表示则为 41,所以下面的写法是等效的:
var ch byte = 65
var ch byte = '\x41'
var ch byte = '\377'(
\x总是紧跟着长度为 2 的 16 进制数)
字符串
字符串是一种值类型,且值不可变,即创建某个文本后你无法再次修改这个文本的内容;更深入地讲,字符串是字节的定长数组。
Go 支持以下 2 种形式的字面值:
解释字符串:
该类字符串使用双引号括起来,其中的相关的转义字符将被替换,这些转义字符包括:
\n:换行符\r:回车符\t:tab 键\u或\U:Unicode 字符\\:反斜杠自身
非解释字符串:
该类字符串使用反引号括起来,支持换行,例如:
This is a raw string \n中的\n\会被原样输出。
和 C/C++不一样,Go 中的字符串是根据长度限定,而非特殊字符 \0。
string 类型的零值为长度为零的字符串,即空字符串 ""。
一般的比较运算符(==、!=、<、<=、>=、>)通过在内存中按字节比较来实现字符串的对比。你可以通过函数 len() 来获取字符串所占的字节长度,例如:len(str)。
字符串的内容(纯字节)可以通过标准索引法来获取,在中括号 [] 内写入索引,索引从 0 开始计数:
- 字符串
str的第 1 个字节:str[0] - 第
i个字节:str[i - 1] - 最后 1 个字节:
str[len(str)-1]
WARNING
获取字符串中某个字节的地址的行为是非法的,例如:&str[i]。
在循环中使用加号 + 拼接字符串并不是最高效的做法,更好的办法是使用函数 strings.Join(),有没有更好的办法了?有!使用字节缓冲(bytes.Buffer)拼接更加给力。
指针
Go 语言为程序员提供了控制数据结构的指针的能力;但是,不能进行指针运算。
通过给予程序员基本内存布局,Go 语言允许你控制特定集合的数据结构、分配的数量以及内存访问模式,这些对构建运行良好的系统是非常重要的:指针对于性能的影响是不言而喻的,而如果你想要做的是系统编程、操作系统或者网络应用,指针更是不可或缺的一部分。
程序在内存中存储它的值,每个内存块(或字)有一个地址,通常用十六进制数表示,如:0x6b0820 或 0xf84001d7f0。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
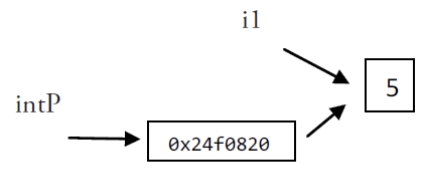
var i1 = 5
fmt.Printf("An integer: %d, it's location in memory: %p\n", i1, &i1)
// 输出
`An integer: 5, its location in memory: 0x6b0820`(这个值随着你每次运行程序而变化)。这个地址可以存储在一个叫做指针的特殊数据类型中,在本例中这是一个指向 int 的指针,即 i1:此处使用 *int 表示。如果我们想调用指针 intP,我们可以这样声明它:
var intP *int然后使用 intP = &i1 是合法的,此时 intP 指向 i1。
(指针的格式化标识符为 %p)
intP 存储了 i1 的内存地址;它指向了 i1 的位置,它引用了变量 i1。
一个指针变量可以指向任何一个值的内存地址 它指向那个值的内存地址,在 32 位机器上占用 4 个字节,在 64 位机器上占用 8 个字节,并且与它所指向的值的大小无关。当然,可以声明指针指向任何类型的值来表明它的原始性或结构性;你可以在指针类型前面加上 * 号(前缀)来获取指针所指向的内容,这里的 * 号是一个类型更改器。使用一个指针引用一个值被称为间接引用。
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
一个指针变量通常缩写为 ptr。
WARNING
在书写表达式类似 var p *type 时,切记在 * 号和指针名称间留有一个空格,因为 - var p*type 是语法正确的,但是在更复杂的表达式中,它容易被误认为是一个乘法表达式!
符号 * 可以放在一个指针前,如 *intP,那么它将得到这个指针指向地址上所存储的值;这被称为反引用(或者内容或者间接引用)操作符;另一种说法是指针转移。
对于任何一个变量 var, 如下表达式都是正确的:var == *(&var)。
package main
import "fmt"
func main() {
var i1 = 5
fmt.Printf("An integer: %d, its location in memory: %p\n", i1, &i1)
var intP *int
intP = &i1
fmt.Printf("The value at memory location %p is %d\n", intP, *intP)
}输出:
An integer: 5, its location in memory: 0x24f0820
The value at memory location 0x24f0820 is 5我们可以用下图来表示内存使用的情况:
TIP
*号在 Go 语言中有两个主要用途:
- 声明一个指针变量,如:
var intP *int。 - 通过指针访问该指针所指向的地址处的值,如:
*intP。
分配一个新的值给 *p 并且更改这个变量自己的值(这里是一个字符串)。
package main
import "fmt"
func main() {
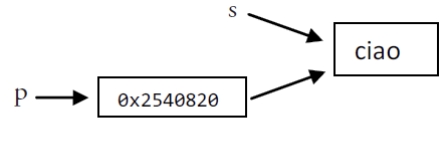
s := "good bye"
var p *string = &s
*p = "ciao"
fmt.Printf("Here is the pointer p: %p\n", p) // prints address
fmt.Printf("Here is the string *p: %s\n", *p) // prints string
fmt.Printf("Here is the string s: %s\n", s) // prints same string
}输出:
Here is the pointer p: 0x2540820
Here is the string *p: ciao
Here is the string s: ciao通过对 *p 赋另一个值来更改“对象”,这样 s 也会随之更改。
内存示意图如下:
WARNING
你不能获取字面量或常量的地址,例如:
const i = 5
ptr := &i //error: cannot take the address of i
ptr2 := &10 //error: cannot take the address of 10所以说,Go 语言和 C、C++ 以及 D 语言这些低级(系统)语言一样,都有指针的概念。但是对于经常导致 C 语言内存泄漏继而程序崩溃的指针运算(所谓的指针算法,如:pointer+2,移动指针指向字符串的字节数或数组的某个位置)是不被允许的。Go 语言中的指针保证了内存安全,更像是 Java、C# 和 VB.NET 中的引用。
因此 p++ 在 Go 语言的代码中是不合法的。
指针的一个高级应用是你可以传递一个变量的引用(如函数的参数),这样不会传递变量的拷贝。指针传递是很廉价的,只占用 4 个或 8 个字节。当程序在工作中需要占用大量的内存,或很多变量,或者两者都有,使用指针会减少内存占用和提高效率。被指向的变量也保存在内存中,直到没有任何指针指向它们,所以从它们被创建开始就具有相互独立的生命周期。
另一方面(虽然不太可能),由于一个指针导致的间接引用(一个进程执行了另一个地址),指针的过度频繁使用也会导致性能下降。
指针也可以指向另一个指针,并且可以进行任意深度的嵌套,导致你可以有多级的间接引用,但在大多数情况这会使你的代码结构不清晰。
如我们所见,在大多数情况下 Go 语言可以使程序员轻松创建指针,并且隐藏间接引用,如:自动反向引用。
对一个空指针的反向引用是不合法的,并且会使程序崩溃:
package main
func main() {
var p *int = nil
*p = 0
}
// in Windows: stops only with: <exit code="-1073741819" msg="process crashed"/>
// runtime error: invalid memory address or nil pointer dereference类型别名
当你在使用某个类型时,你可以给它起另一个名字,然后你就可以在你的代码中使用新的名字(用于简化名称或解决名称冲突)。
在 type TZ int 中,TZ 就是 int 类型的新名称(用于表示程序中的时区),然后就可以使用 TZ 来操作 int 类型的数据。
package main
import "fmt"
type TZ int
func main() {
var a, b TZ = 3, 4
c := a + b
fmt.Printf("c has the value: %d", c) // 输出:c has the value: 7
}实际上,类型别名得到的新类型并非和原类型完全相同,新类型不会拥有原类型所附带的方法。
类型转换
在必要以及可行的情况下,一个类型的值可以被转换成另一种类型的值。由于 Go 语言不存在隐式类型转换,因此所有的转换都必须显式说明,就像调用一个函数一样(类型在这里的作用可以看作是一种函数):
valueOfTypeB = typeB(valueOfTypeA)类型 B 的值 = 类型 B(类型 A 的值)
示例:
a := 5.0
b := int(a)但这只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(例如将 int16 转换为 int32)。当从一个取值范围较大的转换到取值范围较小的类型时(例如将 int32 转换为 int16 或将 float32 转换为 int),会发生精度丢失(截断)的情况。当编译器捕捉到非法的类型转换时会引发编译时错误,否则将引发运行时错误。
具有相同底层类型的变量之间可以相互转换:
var a IZ = 5
c := int(a)
d := IZ(c)